

此部分的作者名:yjy
TCP/IP的三次握手和四次挥手
首先简单介绍一下HTTP工作流程:
- DNS 解析 客户端将域名(如
www.baidu.com)解析为 IP 地址。 - TCP 三次握手 建立连接(SYN → SYN-ACK → ACK)
- 发送 HTTP 请求 & 接收响应 客户端发送请求报文,服务器返回响应报文
- TCP 四次挥手断开连接
TCP三次握手
建立一个 TCP 连接需要“三次握手”,缺一不可:
- 第一次握手 (SYN): 客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含一个由客户端随机生成的初始序列号(Initial Sequence Number, ISN),例如 seq=x。发送后,客户端进入 SYN_SEND 状态,等待服务端的确认。
- 第二次握手 (SYN+ACK) : 服务端收到 SYN 报文段后,如果同意建立连接,会向客户端回复一个确认报文段。该报文段包含两个关键信息:
- SYN:服务端也需要同步自己的初始序列号,因此报文段中也包含一个由服务端随机生成的初始序列号,例如 seq=y。
- ACK (Acknowledgement):用于确认收到了客户端的请求。其确认号被设置为客户端初始序列号加一,即 ack=x+1。
- 发送该报文段后,服务端进入 SYN_RECV 状态。
(注意:TCP第二次挥手会占用少量内存,在该状态下若黑客伪造海量虚假客户端发送FIN报文,但不发送第三次挥手,将会耗尽服务器端口、内存资源,导致正常连接无法建立)
3.第三次握手 (ACK): 客户端收到服务端的 SYN+ACK 报文段后,会向服务端发送一个最终的确认报文段。该报文段包含确认号 ack=y+1。发送后,客户端进入 ESTABLISHED 状态。服务端收到这个 ACK 报文段后,也进入 ESTABLISHED 状态。
至此,双方都确认了连接的建立,TCP 连接成功创建,可以开始进行双向数据传输。
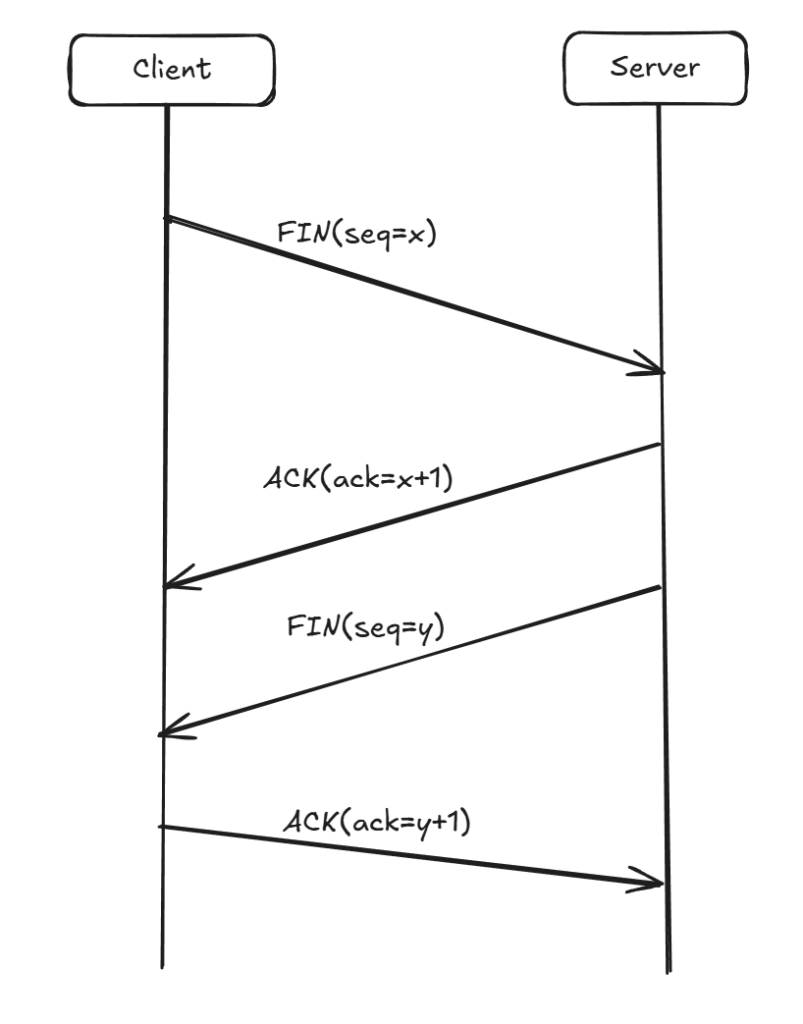
TCP四次挥手
断开一个 TCP 连接则需要“四次挥手”,缺一不可:
- 第一次挥手 (FIN):当客户端(或任何一方)决定关闭连接时,它会向服务端发送一个 FIN(Finish)标志的报文段,表示自己已经没有数据要发送了。该报文段包含一个序列号 seq=u。发送后,客户端进入 FIN-WAIT-1 状态。
- 第二次挥手 (ACK):服务端收到 FIN 报文段后,会立即回复一个 ACK 确认报文段。其确认号为 ack=u+1。发送后,服务端进入 CLOSE-WAIT 状态。客户端收到这个 ACK 后,进入 FIN-WAIT-2 状态。此时,TCP 连接处于半关闭(Half-Close)状态:客户端到服务端的发送通道已关闭,但服务端到客户端的发送通道仍然可以传输数据。
- 第三次挥手 (FIN):当服务端确认所有待发送的数据都已发送完毕后,它也会向客户端发送一个 FIN 报文段,表示自己也准备关闭连接。该报文段同样包含一个序列号 seq=y。发送后,服务端进入 LAST-ACK 状态,等待客户端的最终确认。
- 第四次挥手:客户端收到服务端的 FIN 报文段后,会回复一个最终的 ACK 确认报文段,确认号为 ack=y+1。发送后,客户端进入 TIME-WAIT 状态。服务端在收到这个 ACK 后,立即进入 CLOSED 状态,完成连接关闭。客户端则会在 TIME-WAIT 状态下等待 2MSL(Maximum Segment Lifetime,报文段最大生存时间)后,才最终进入 CLOSED 状态。
只要四次挥手没有结束,客户端和服务端就可以继续传输数据!
URL和URI
URL
一、URL 的核心结构
一个标准的 URL 通常由8 个部分组成(部分场景下某些组件可省略),各部分用特定符号分隔,功能明确。以示例 https://www.example.com:8080/path/file.html?name=test&age=20#section1 为例,结构拆解如下:
| 组件名称 | 示例内容 | 功能说明 |
|---|---|---|
| 协议(Scheme) | https | 规定浏览器与服务器的通信规则(如传输方式、数据加密等),常见协议见下文。 |
| 分隔符 | :// | 固定分隔符,用于区分 “协议” 和后续内容。 |
| 子域名(Subdomain) | www | 域名的细分,通常用于指定服务类型(如www代表网页服务,mail代表邮箱)。 |
| 主域名(Domain) | example | 资源所属网站的核心标识,需通过域名注册商申请(如baidu、google)。 |
| 顶级域名(TLD) | .com | 域名的最高层级,代表网站类型或所属地区(如.com商业、.org非营利、.cn中国)。 |
| 端口(Port) | :8080 | 服务器上用于接收特定服务的 “通道号”,默认端口可省略(如 HTTP 默认 80,HTTPS 默认 443)。 |
| 路径(Path) | /path/file.html | 资源在服务器中的具体存储位置(类似电脑中的 “文件夹 / 文件名”)。 |
| 查询参数(Query) | ?name=test&age=20 | 向服务器传递额外信息(如搜索关键词、表单数据),格式为 “参数名 = 值”,多参数用&分隔。 |
| 锚点(Fragment) | #section1 | 定位网页内的具体位置(如某段落、标题),仅在浏览器端生效,不发送给服务器。 |
二、常见的 URL 协议(Scheme)
不同协议对应不同的资源类型和交互规则,常见类型如下:
http:超文本传输协议(HyperText Transfer Protocol),早期网页常用,数据传输不加密,安全性较低,现在逐渐被 HTTPS 替代。https:HTTP 的加密版本(HTTP Secure),通过 SSL/TLS 协议加密数据,能防止传输过程中被窃取或篡改,常用于支付、登录等敏感场景(浏览器地址栏会显示 “小锁” 图标)。ftp/ftps:文件传输协议(File Transfer Protocol),用于在本地与服务器间传输文件,ftps是加密版本。file:用于访问本地计算机中的文件(非网络资源),示例:file:///C:/Users/Documents/test.txt(Windows)或file:///Users/xxx/Documents/test.txt(Mac)。mailto:点击后直接调用本地邮件客户端发送邮件,示例:mailto:example@xxx.com?subject=测试邮件(subject指定邮件主题)。tel:在移动端点击后直接触发拨号,示例:tel:10086。
三、URL 的关键特性
- 唯一性:每个资源的 URL 在网络中是唯一的(理论上),确保不会定位到错误资源。
- 可读性:域名部分(如
www.baidu.com)设计为人类可记忆的形式,避免直接使用 IP 地址(如180.101.49.11)。 - 编码需求:URL 中不能包含空格、中文、特殊符号(如
&、#),需通过 “URL 编码” 转换为合法字符(如空格→%20,中文 “测试”→%E6%B5%8B%E8%AF%95),浏览器会自动处理部分编码,但手动构造 URL 时需注意。
URI
URI(Uniform Resource Identifier,统一资源标识符)是用于唯一标识互联网或本地系统中资源的字符串格式,其核心作用是 “识别资源”,不强制要求 “如何获取资源”。它是一个更宽泛的概念,URL(统一资源定位符)本质上是 URI 的一种具体实现(即能定位资源的 URI)。
一、URI 的核心定义与分类
URI 的核心是 “标识”—— 无论资源是网页、文件、数据库记录还是邮件地址,只要通过一个字符串能唯一区分它,这个字符串就是 URI。根据是否能 “定位资源”(即提供获取资源的路径 / 方法),URI 主要分为两大类别:
| 类别 | 全称 | 核心功能 | 关系说明 | 示例 |
|---|---|---|---|---|
| URL | Uniform Resource Locator | 不仅标识资源,还提供获取资源的具体地址和协议(即 “定位 + 标识”) | URI 的子集(可定位的 URI) | https://www.baidu.com(网页)、ftp://ftp.example.com/file.zip(文件) |
| URN | Uniform Resource Name | 仅永久标识资源,不提供获取路径(即 “纯标识,不定位”) | URI 的子集(不可定位的 URI) | urn:isbn:9787115546926(ISBN 书号,标识某本书,但不告诉在哪下载 / 购买)、urn:uuid:6ba7b810-9dad-11d1-80b4-00c04fd430c8(通用唯一识别码,标识某一实体) |
简单来说:所有 URL 都是 URI,但并非所有 URI 都是 URL——URN 是 URI 中仅用于 “标识” 而不 “定位” 的类型。
二、URI 的通用结构
URI 的结构遵循 RFC 3986(互联网标准文档)的规范,核心由5 个可选组件构成(不同类型的 URI 会省略部分组件),通用格式如下:
[scheme]:[scheme-specific-part][#fragment]
各组件的含义与约束如下:
| 组件名称 | 功能说明 | 约束与示例 |
|---|---|---|
| 方案(Scheme) | 定义资源的类型或标识规则,必须以字母开头,后续可包含字母、数字、+、-、. | 不同 Scheme 对应不同的资源类型,如:- http/https(网络资源)- urn(永久标识资源)- mailto(邮件地址)- file(本地文件) |
| 方案特定部分(Scheme-Specific Part) | 由 Scheme 决定格式,是 URI 的核心内容,用于具体标识资源 | 例如:- http的 Scheme 特定部分是//www.baidu.com/index.html(包含域名、路径)- urn的 Scheme 特定部分是isbn:9787115546926(包含标识类型和具体编码)- mailto的 Scheme 特定部分是example@xxx.com(邮件地址) |
| 片段(Fragment) | 用于标识资源内部的子部分(如网页中的某段落、文档中的某章节),仅在客户端生效,不传递给服务器 | 以#开头,例如https://example.com/docs#chapter2(标识文档的 “第 2 章”)、urn:isbn:9787115546926#page10(标识书的 “第 100 页”) |
三、URI 与 URL 的核心区别!!!
很多人会混淆 URI 和 URL,两者的核心差异在于 “功能范围”,可通过下表清晰区分:
| 对比维度 | URI(统一资源标识符) | URL(统一资源定位符) |
|---|---|---|
| 核心功能 | 标识资源(唯一区分资源,不关心如何获取) | 标识 + 定位资源(不仅区分资源,还告诉如何获取) |
| 范围 | 更宽泛,包含 URL 和 URN | 更具体,是 URI 的子集 |
| 是否依赖 “位置” | 不依赖(如 URN 通过 ISBN 标识书,与书的存储位置无关) | 依赖(必须包含资源的存储地址,如域名、路径) |
| 示例 | urn:isbn:9787115546926(仅标识书)、mailto:example@xxx.com(仅标识邮件地址) | https://www.baidu.com(标识并定位网页)、ftp://ftp.example.com/file.zip(标识并定位文件) |
一句话总结:URI 是 “资源的身份证”,URL 是 “资源的身份证 + 住址”。
四、常见的 URI 类型(除 URL 外)
除了大家熟悉的 URL,日常场景中还有不少非 URL 的 URI(即 URN 或其他标识型 URI),常见类型如下:
- URN(永久标识资源)
urn:isbn:9787302599989:通过 ISBN 书号标识《Python 编程:从入门到实践》这本书,无论这本书的电子版存储在哪个服务器,这个 URN 始终不变。urn:ietf:rfc:3986:标识互联网标准文档 RFC 3986(即定义 URI 的文档),与文档的下载地址无关。
- mailto URI
mailto:support@example.com?subject=问题反馈:标识 “发送邮件给 support@example.com” 这一资源,仅说明 “要发给谁”,不强制 “用哪个邮件客户端发送”(属于 “标识行为资源” 的 URI,非 URL)。
- tel URI
tel:+8610123456789:标识 “拨打 + 8610123456789 这个号码” 的资源,仅说明 “要拨哪个号”,不强制 “用哪个设备拨号”(移动端点击后会触发拨号,本质是 URI 的应用,非严格意义上的 URL)。
五、URI 的关键特性
- 唯一性:同一资源在同一语境下的 URI 必须唯一(如一本书的 ISBN URN 全球唯一,一个网页的 URL 在网络中唯一)。
- 独立性:非 URL 类型的 URI(如 URN)不依赖资源的存储位置 —— 即使资源的存储地址变化(如一本书的电子版从 A 服务器迁移到 B 服务器),其 URN 仍不变。
- 灵活性:Scheme 可扩展,除了常见的
http、urn,还可自定义 Scheme(如企业内部系统用company:user:123标识员工 ID 为 123 的用户)。
六、常见误区
- 混淆 “URI” 与 “URL”:认为两者是 “并列关系”,实际是 “包含关系”(URL⊂URI)。
- 忽略 URN 的存在:日常场景中 URL 更常用(如浏览器输入的都是 URL),但 URN 在需要 “永久标识资源” 的场景(如图书、标准文档)中至关重要。
- 误解 “URI 必须联网”:URI 可标识本地资源(如
file:///C:/Users/test.txt是本地文件的 URI,同时也是 URL),并非仅限互联网资源。
公网和内网
打一个很形象的比方:
- 公网 (Internet / Public Network) 就像覆盖全球的公共道路交通系统(高速公路、国道、城市道路)。它四通八达,任何一个有合法“地址”(公网IP)的设备都可以通过它访问世界各地的其他设备。
- 内网 (Intranet / Private Network) 就像你家的私人住宅或小区。在你家里(内网),每个房间(电脑、手机、智能电视)都有自己内部的门牌号(内网IP,如192.168.x.x),它们之间可以方便地互相访问。但整个家对外只有一个公共地址(公网IP),这个地址是市政统一分配的。
一、公网 (Public Network)
- 定义: 公网就是互联网,是全球性的、开放的计算机网络系统。它由全球无数个网络相互连接而成,任何人都可以按照规则接入和使用。
- 核心特点:
- 全球唯一性:公网上的每个设备都有一个全球唯一的身份标识,即公网IP地址(如
120.244.66.123)。就像世界上没有两个完全相同的邮寄地址一样。 - 公开可访问:只要你知道一个服务器的公网IP和端口,理论上可以从世界任何地方访问它(除非有防火墙等安全限制)。
- 规模巨大:由无数网络设备(路由器、交换机、光缆等)组成,覆盖全球。
- 资源丰富:我们日常使用的所有互联网服务(如百度、淘宝、微信、Netflix、Google)都位于公网上。
- 全球唯一性:公网上的每个设备都有一个全球唯一的身份标识,即公网IP地址(如
- 管理:由专门的机构(如ICANN、各地的ISP互联网服务提供商)统一管理和分配IP地址等。
二、内网 (Private Network)
- 定义: 内网是一个私有的、局部的网络,通常属于某个组织、家庭或个人。它不与公网直接混杂,而是通过一个或多个网关(通常是路由器)与公网连接。
- 核心特点:
- 地址可重用:内网使用的IP地址段是专门保留的私有IP地址段。这些地址在任何内网中都可以重复使用,但无法在公网上被直接路由。
- 常用私有地址段:
10.0.0.0-10.255.255.255(大型企业)172.16.0.0-172.31.255.255(中型企业)192.168.0.0-192.168.255.255(家庭和小型办公室最常见,如192.168.1.101)
- 常用私有地址段:
- 私有性和安全性:外部公网的用户无法直接访问内网中的设备,这提供了一个天然的安全屏障(即网络地址转换NAT带来的安全效应)。
- 高速低成本:内网内的设备通信速度极快(如局域网传文件),且不消耗公网流量。
- 地址可重用:内网使用的IP地址段是专门保留的私有IP地址段。这些地址在任何内网中都可以重复使用,但无法在公网上被直接路由。
- 典型场景:
- 家庭网络:你的手机、电脑、打印机都通过Wi-Fi连接到家里的路由器,组成了一个内网。
- 公司/校园网:公司内部的所有电脑和服务器组成一个大的内网,方便内部数据共享和通信。
三、核心区别与联系(含NAT技术)
| 特性 | 公网 (Internet) | 内网 (Intranet) |
|---|---|---|
| 范围 | 全球性 | 局部性(家庭、公司、学校) |
| IP地址 | 公网IP,全球唯一 | 私有IP,可重复使用 |
| 访问性 | 公开,可被任何联网设备访问 | 私有,外部无法直接访问 |
| 管理方 | ICANN, ISP等机构 | 个人或组织自行管理 |
| 成本 | 需要向ISP支付费用 | 内部通信免费 |
| 主要目的 | 全球范围内的信息交换 | 内部资源共享和通信 |
它们是如何联系的?—— 关键:NAT(网络地址转换) 由于公网IP地址是稀缺资源,不可能给每个手机、电脑都分配一个。因此,我们使用路由器作为中介。
- 运营商给你的家庭或公司只分配一个公网IP地址。
- 路由器连接公网,拥有这个公网IP。同时,它创建一个内网,并给内网中的每个设备(你的电脑、手机)分配一个私有IP(如
192.168.1.101)。 - 当你的电脑(
192.168.1.101)想要访问百度(一个公网IP)时:- 数据包从你的电脑发出,目标地址是百度的公网IP,源地址是你的内网IP
192.168.1.101。 - 数据包经过路由器时,路由器会执行 NAT 操作:将数据包的源IP地址,从你的内网IP(
192.168.1.101)修改为路由器自己的公网IP,并记录下这个连接(方便回传数据)。 - 百度服务器收到请求后,以为是与你的路由器公网IP在通信,于是将响应数据发回给你的路由器公网IP。
- 路由器收到响应后,根据之前记录的连接信息,准确地将数据包转发给你的电脑(
192.168.1.101)。
- 数据包从你的电脑发出,目标地址是百度的公网IP,源地址是你的内网IP
这个过程使得内网的多台设备可以“共享”一个公网IP上网,既节约了IP地址,又隐藏了内网结构,增强了安全性。
端口
如果说 IP 地址像是房子的具体地址(例如:上海市浦东新区张江高科某某路100号),它负责把数据包准确地送到目标设备所在的“建筑”,那么 端口 就是这栋建筑里的具体房间号(例如:100号建筑的301房间、808房间)。
一、端口是什么?
- 官方定义: 端口是网络通信中设备内部的一个抽象的“通道”或“门牌号”。它在逻辑上代表一个网络服务或应用程序的入口点。
- 通俗理解: 一台电脑(服务器)可能同时提供多种网络服务,比如网页服务、文件传输服务、电子邮件服务。当外部的数据包通过IP地址找到这台电脑后,电脑需要知道这个数据包是发给哪个“服务程序”的。端口就是用来做这件事的“分流器”。
- 关键点:
- 范围:端口号是一个 16 位的整数,范围是 0 ~ 65535。
- 格式:端口号与IP地址共同工作,格式为
IP地址:端口号,例如192.168.1.1:80。
二、为什么需要端口?
想象一下公司的前台:
- IP 地址 = 公司大楼地址
- 端口 = 公司内部各个部门的分机号(如:销售部请按 1,技术支持请按 2,财务部请按 3...)
如果没有端口(分机号),数据包到了目标设备(公司大楼)就不知道应该交给哪个应用程序(部门)处理,会导致通信混乱。端口实现了一台设备上的多个网络应用程序可以同时独立工作,互不干扰。
三、端口的分类
端口号分为三大类,这个分类非常重要:
1. 知名端口 (Well-Known Ports)
- 范围:0 - 1023
- 作用:这些端口号固定分配给最常用、最重要的网络服务。通常由系统级进程或管理员权限的程序使用。
- 示例:
- 80: HTTP(网页服务)
- 443: HTTPS(加密的网页服务)
- 21: FTP(文件传输)
- 22: SSH(安全远程登录)
- 25: SMTP(发送邮件)
- 53: DNS(域名解析)
2. 注册端口 (Registered Ports)
- 范围:1024 - 49151
- 作用:分配给一些非系统核心的、但比较常见的应用程序或服务。许多软件厂商会为自己产品注册一个端口。
- 示例:
- 1433: Microsoft SQL Server 数据库
- 1521: Oracle 数据库
- 3306: MySQL 数据库
- 3389: Windows 远程桌面 (RDP)
- 5432: PostgreSQL 数据库
- 6379: Redis 数据库
3. 动态/私有端口 (Dynamic/Private Ports)
- 范围:49152 - 65535
- 作用:客户端使用的端口。当你的电脑(客户端)访问一个网站(如百度)时,你的操作系统会随机从这段端口号中选取一个作为本次连接的“源端口”。这个端口是临时的,连接结束后就会被释放。
- 简单记:服务端用“固定小号”,客户端用“随机大号”。
四、端口的工作流程:一个完整例子
让我们结合之前学的 IP 地址 和 NAT,看一个完整的网页访问流程,理解端口如何工作:
- 你在浏览器输入
www.baidu.com并回车。 - DNS解析:你的电脑先将域名解析成百度的IP地址,例如
110.242.68.4。 - 创建请求:你的浏览器准备发送一个HTTP请求。目标地址是
110.242.68.4,目标端口是80(因为HTTP服务默认在80端口)。 - 分配源端口:你的操作系统为这个连接随机分配一个源端口,例如
55000(从动态端口中选)。所以完整的请求信息是:- 源:
[你的内网IP]:55000(如192.168.1.101:55000) - 目标:
[百度IP]:80(如110.242.68.4:80)
- 源:
- 经过路由器(NAT):数据包到达你的路由器。路由器不仅进行IP地址转换(NAT),还会进行端口转换(NAPT/PAT)。它可能会将你的内网端口
55000映射到路由器自己的一个随机公网端口上,例如62001。- 转换后,数据包变为:
- 源:
[你的公网IP]:62001(如120.244.66.123:62001) - 目标:
110.242.68.4:80
- 百度响应:百度服务器收到请求后,会向
120.244.66.123:62001发送响应。 - 路由器转发:你的路由器收到响应,查看自己的NAT转换表,发现公网端口
62001对应内网设备192.168.1.101的端口55000。于是它将数据包转发给你的电脑。 - 浏览器接收:你的电脑收到数据包,操作系统根据目标端口
55000确定这个数据包是属于你刚才发起的那个浏览器标签页的,于是将数据交给浏览器处理。 - 网页显示:浏览器解析数据,网页内容就显示出来了。
五、端口与安全
端口是计算机与外界通信的通道,因此也是网络攻击的主要入口。端口扫描 是黑客的常用手段,目的是探测目标机器上打开了哪些端口,从而判断运行了哪些服务,并寻找漏洞。因此,网络安全的一个重要原则是:“最小权限原则”,即只开放必要的端口,关闭所有不需要的端口。这就是防火墙 的主要工作之一——控制哪些端口的流量可以进出。
总结
| 概念 | 比喻 | 作用 |
|---|---|---|
| IP 地址 | 大楼地址 | 定位网络中的设备(哪台电脑) |
| 端口 | 房间号/分机号 | 定位设备上的应用程序/服务(哪个程序) |
| 端口号范围 | 0-65535 | 其中 0-1023 是著名服务端口,1024-49151 是注册端口,49152-65535 是客户端临时端口。 |
简单来说,IP 地址负责网络层的寻址(找到设备),而端口负责传输层的寻址(找到设备上的正确程序)。两者结合,才能完成一次精准的网络通信。
OSI七层参考模型
这个模型是理解网络通信如何一步步实现的“地图”。它将一个复杂的网络通信过程分解成七个独立的、各司其职的层次,每一层都为上一层提供服务,并使用下一层的服务。
一、什么是OSI模型?
- 定义:OSI模型是一个由国际标准化组织提出的概念性框架,它使用分层结构将网络通信的工作划分为七个更小、更易于管理的部分。
- 核心思想:分层与封装。发送方数据从最高层(应用层)向下传递,每经过一层都会被“打包”一次,添加本层的头部信息(封装);接收方则从最低层(物理层)向上传递,逐层“拆包”(解封装),最终还原为原始数据。
为了帮助记忆,可以背这个口诀:All People Seem To Need Data Processing(所有人似乎都需要数据处理)。
- A - Application (应用层)
- P - Presentation (表示层)
- S - Session (会话层)
- T - Transport (传输层)
- N - Network (网络层)
- D - Data Link (数据链路层)
- P - Physical (物理层)
二、七层结构详解(从下到上)
第1层:物理层
- 功能:定义物理标准,负责在物理介质上传输原始的比特流(就是0和1的信号)。它关心的是电压、线缆规格、接口类型、信号时序等。
- 关键设备:网线、光纤、集线器、中继器。
- 数据单位:比特。
- 比喻:公路和卡车。物理层就是负责运输的“公路”和“卡车”本身,它只关心能不能把货物(比特流)从一个地方 physically 运到另一个地方,不关心货物是什么。
第2层:数据链路层
- 功能:负责在同一个局域网内的节点到节点(如交换机到电脑)的数据传输。它将物理层的比特流封装成“帧”,并进行差错校验。最重要的子层是 MAC 子层,管理MAC地址(设备的物理地址)。
- 关键设备:交换机(通过MAC地址转发数据)。
- 数据单位:帧。
- 比喻:顺丰在上海的集散中心。它负责把要寄出的多个包裹(数据帧)打上标签(源/目标MAC地址),并检查从卡车上卸下的包裹(数据帧)是否完好(差错控制)。它只关心上海市内的运输。
第3层:网络层
- 功能:负责在不同网络之间(即从上海到北京)进行逻辑寻址和路径选择(路由)。它的核心任务是将数据包从源主机跨网络送达目标主机。
- 关键协议:IP协议。
- 关键设备:路由器。
- 数据单位:包/分组。
- 比喻:顺丰的全国路由规划系统。它关心的是这封信应该走哪条路线(路由选择)才能从上海送到北京。它给包裹贴上“全国通用”的地址标签(IP地址)。这是实现“网际互连”的关键一层。
第4层:传输层
- 功能:负责端到端的通信,即进程到进程的通信。它解决了数据如何可靠、有序、无差错地送达目标主机的具体应用程序。
- 关键协议:
- TCP:面向连接、可靠传输(如打电话,需要确认对方收到)。速度慢,但可靠。
- UDP:无连接、不可靠传输(如发广播、发短信)。速度快,但可能丢失。
- 数据单位:段。
- 比喻:区分收件人公司的不同部门。网络层把包裹送到了公司大楼(目标IP地址),传输层则根据包裹上的“部门代码”(端口号,如80端口是给网页服务部的,25端口是给邮件服务部的)把包裹分发给正确的部门(应用程序)。TCP负责确保包裹完好无损地送到(可靠传输),UDP则可能直接扔过去不管。
【下三层 vs 上四层】
- 下三层(物理、数据链路、网络):关心的是“数据如何通过网络传输”,是网络工程师关注的重点。
- 上四层(传输、会话、表示、应用):关心的是“数据如何被应用程序理解和使用的”,是软件开发人员关注的重点。
第5层:会话层
- 功能:负责建立、管理和终止两个应用进程之间的会话(Session)。比如在通信过程中进行认证、权限管理,以及决定使用全双工还是半双工通信。
- 比喻:一次完整的电话通话。会话层负责拨号(建立连接)、通话(维持连接)、以及说再见后挂断电话(终止连接)。它管理的是“一次完整的通信过程”。
第6层:表示层
- 功能:负责数据的表示格式。比如数据加密/解密、压缩/解压缩、以及格式转换(如将GBK编码转换为UTF-8编码),确保一个系统应用层发出的信息能被另一个系统的应用层读懂。
- 比喻:翻译官和密码员。你的朋友只懂英文,而你写了中文信。表示层就像翻译官,负责把中文翻译成英文(格式转换)。或者,它把信件内容加密(加密),防止别人偷看。
第7层:应用层
- 功能:最靠近用户的一层,为应用程序提供网络服务接口。我们日常使用的网络应用都基于这一层的协议。
- 关键协议:HTTP(网页)、HTTPS(安全网页)、FTP(文件传输)、SMTP/POP3(电子邮件)、DNS(域名解析)。
- 比喻:你写的信的内容本身。应用层就是你所使用的具体服务,比如你写这封信(使用HTTP协议访问网页),或者你通过微信发送消息(使用另一种应用层协议)。这一层是用户真正能“看到”和“用到”的。
三、数据封装与解封装流程
这是理解OSI模型如何工作的关键:发送方(封装过程):“打包”
- 用户在应用层(第7层)产生数据(如一封邮件)。
- 数据向下传递到表示层(第6层),被加密或压缩。
- 继续向下到会话层(第5层),建立会话信息。
- 到达传输层(第4层),数据被加上TCP或UDP头部,包含端口号,变成数据段。
- 到达网络层(第3层),被加上IP头部,包含源/目标IP地址,变成数据包。
- 到达数据链路层(第2层),被加上帧头部和尾部,包含MAC地址,变成数据帧。
- 到达物理层(第1层),数据帧被转换为0和1的比特流,通过网线/光纤等发送出去。
接收方(解封装过程):“拆包”过程完全相反,从物理层开始,逐层向上,每一层拆掉对应的头部,最终将原始数据交给目标应用程序。
四、现实世界:TCP/IP模型
需要注意的是,OSI是一个理论模型,而现实中广泛使用的是更简洁的 TCP/IP 四层模型。它们的对应关系如下:
| OSI 七层模型 | TCP/IP 四层模型 | 协议示例 | 数据单位 |
|---|---|---|---|
| 应用层、表示层、会话层 | 应用层 | HTTP, FTP, DNS, SMTP | 数据流 |
| 传输层 | 传输层 | TCP, UDP | 数据段 |
| 网络层 | 网络层 | IP, ICMP | 数据包 |
| 数据链路层、物理层 | 网络接口层 | Ethernet, WiFi | 帧/比特流 |
总结
OSI模型的价值在于它提供了一个标准化的思考框架,帮助我们:
- 理解网络通信:将复杂过程模块化,便于学习和排查故障。
- 开发网络产品:不同厂商可以基于统一标准开发兼容的设备和服务。
- 解决网络问题:当网络出现故障时,可以逐层排查,快速定位问题所在(是物理线路坏了?还是IP配置错了?或是防火墙端口没开?)。
记住这个核心:OSI模型的核心思想是分层、封装与解封装。
此部分作者:szy
Comments NOTHING